為異構的大數(shù)據(jù)運行環(huán)境構建數(shù)據(jù)管道
據(jù)運行環(huán)境構建數(shù)據(jù)管道")
Pipeline61框架可以用于為異構的運行環(huán)境構建數(shù)據(jù)管道。它可以重用已經(jīng)部署在各個環(huán)境里的作業(yè)代碼,并提供了版本控制和依賴管理來解決典型的軟件工程問題。
研究人員開發(fā)了大數(shù)據(jù)處理框架,如MapReduce和Spark,用于處理分布在大規(guī)模集群里的大數(shù)據(jù)集。這些框架著實降低了開發(fā)大數(shù)據(jù)應用程序的復雜度。在實際當中,有很多的真實場景要求將多個數(shù)據(jù)處理和數(shù)據(jù)分析作業(yè)進行管道化和集成。例如,圖像分析應用要求一些預處理步驟,如圖像解析和特征抽取,而機器學習算法是整個分析流里唯一的核心組件。不過,要對已經(jīng)開發(fā)好的作業(yè)進行管道化和集成,以便支持更為復雜的數(shù)據(jù)分析場景,并不是一件容易的事。為了將運行在異構運行環(huán)境里的數(shù)據(jù)作業(yè)集成起來,開發(fā)人員必須寫很多膠水代碼,讓數(shù)據(jù)在這些作業(yè)間流入流出。Google的一項研究表明,一個成熟的系統(tǒng)可能只包含了5%的機器學習代碼,而剩下的95%都是膠水代碼。
為了支持對大數(shù)據(jù)作業(yè)進行管道化和集成,研究人員推薦使用高級的管道框架,如Crunch、Pig和Cascading等。這些框架大都是基于單一的數(shù)據(jù)處理運行環(huán)境而構建的,并要求使用特定的接口和編程范式來構建管道。況且,管道應用需要不斷演化,滿足新的變更和需求。這些應用還有可能包含各種遺留的組件,它們需要不同的運行環(huán)境。因此,維護和管理這些管道變得非常復雜和耗時。
Pipeline61框架旨在為在異構的運行環(huán)境里維護和管理數(shù)據(jù)管道減少精力的投入,而不需要重寫原有的作業(yè)。它可以將運行在各種環(huán)境里的數(shù)據(jù)處理組件集成起來,包括MapReduce、Spark和腳本。它盡可能重用現(xiàn)有的數(shù)據(jù)處理組件,開發(fā)人員就沒有必要重新學習新的編程范式。除此之外,它為每個管道的數(shù)據(jù)和組件提供了自動化的版本控制和依賴管理。
現(xiàn)有的管道框架
大多數(shù)用于構建管道化大數(shù)據(jù)作業(yè)的框架都是基于單一的處理引擎而構建的(比如Hadoop),并使用了外部的持久化服務(比如Hadoop分布式文件系統(tǒng))來交換數(shù)據(jù)。表A比較了幾種最為重要的管道框架。
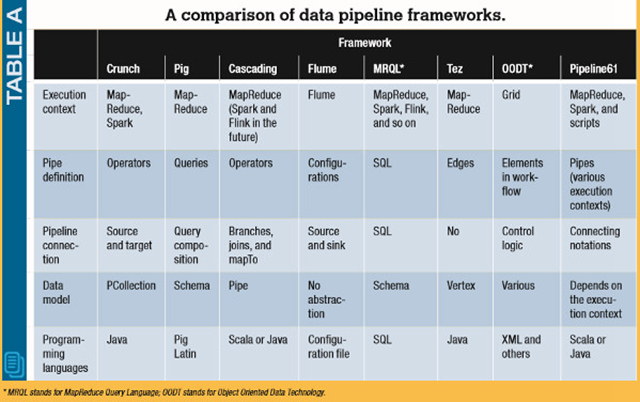
Crunch定義了自己的數(shù)據(jù)模型和編程范式,用于支持管道的寫入,并在MapReduce和Spark上運行管道作業(yè)。Pig使用了一種基于數(shù)據(jù)流的編程范式來編寫ETL(抽取、轉換、加載)腳本,并在執(zhí)行期被轉換成MapReduce作業(yè)。Cascading為管道提供了基于操作符的編程接口,并支持在MapReduce上運行Cascading應用。Flume最初是為基于日志的管道而設計的,用戶通過配置文件和參數(shù)來創(chuàng)建管道。MRQL(MapReduce查詢語言)是一種通用的系統(tǒng),用于在各種運行環(huán)境上進行查詢和優(yōu)化,如Hadoop、Spark和Flink。Tez是一個基于有向無環(huán)圖的優(yōu)化框架,它可以用于優(yōu)化使用Pig和Hive編寫的MapReduce管道。
Pipeline61與這些框架的不同點在于:
- 支持對異構的數(shù)據(jù)處理作業(yè)(MapReduce、Spark和腳本)進行管道化和集成。
- 重用現(xiàn)有的編程范式,而不是要求開發(fā)人員學習新的編程范式。
- 提供自動化的版本控制和依賴管理,具備歷史可追蹤性和可重現(xiàn)性,這些對于管道的持續(xù)開發(fā)來說是非常重要的。
與Pipeline61類似,Apache Object Oriented Data Technology(OODT)數(shù)據(jù)柵格框架支持讓用戶從異構環(huán)境中捕捉、定位和訪問數(shù)據(jù)。與Pipeline61相比,OODT提供了更具通用性的任務驅(qū)動工作流執(zhí)行過程,開發(fā)人員必須編寫程序來調(diào)用不同的任務。相反,Pipeline61專注于與當前的大數(shù)據(jù)處理框架進行深度集成,包括Spark、MapReduce和IPython。OODT使用了基于XML的管道配置,而Pipeline61為各種編程語言提供了編程接口。***,OODT需要維護數(shù)據(jù)集的一般性信息和元數(shù)據(jù)。Pipeline61為管道里的IO數(shù)據(jù)和轉換任務提供了顯式的來源信息。因此,Pipeline61原生地支持歷史數(shù)據(jù)管道或部分數(shù)據(jù)管道的重新生成和重新執(zhí)行。
一個有趣的例子
我們的例子是一個嫌疑檢測系統(tǒng),圖1展示了該系統(tǒng)的數(shù)據(jù)處理管道。系統(tǒng)收集來自各個部門和組織的數(shù)據(jù),比如來自政府道路服務部門的機動車注冊記錄、來自政府稅務部門的個人收入報告,或來自航空公司的航程記錄。來自不同數(shù)據(jù)源的記錄可能具有不同的格式,如CSV、文本、JSON,它們的結構是不一樣的。
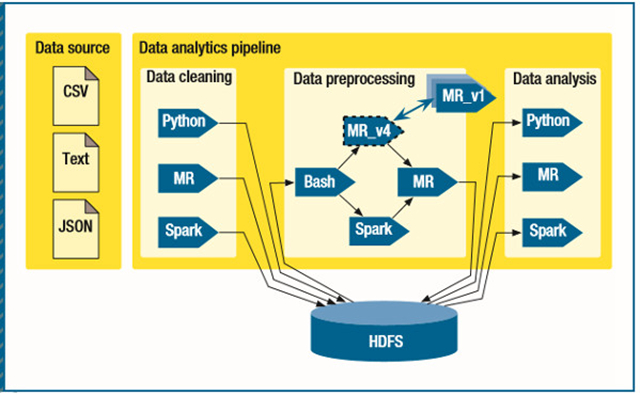
圖1.嫌疑檢測系統(tǒng)的數(shù)據(jù)處理管道。來自不同部門和組織的數(shù)據(jù)可能具有不同的格式和結構。CSV表示以逗號分隔的數(shù)據(jù)值,JSON表示JavaScript Object Notation,MR表示MapReduce,HDFS是Hadoop分布式文件系統(tǒng)。
在數(shù)據(jù)管道的各個階段,不同的數(shù)據(jù)科學家或工程師們可能使用不同的技術和框架來開發(fā)數(shù)據(jù)處理組件,比如IPython、MapReduce、R和Spark。一些遺留的組件也可以通過Bash腳本或第三方軟件進行集成。所以,管理和維護異構環(huán)境里持續(xù)變化的數(shù)據(jù)管道是一個復雜而沉悶的任務。使用新框架替代舊框架的代價是很高的,或許更加難以承受。在最壞的情況下,開發(fā)人員可能需要重新實現(xiàn)所有的數(shù)據(jù)處理組件。
另外,正如我們之前提過的那樣,為了滿足新的系統(tǒng)變更需求,管道應用程序需要保持演化和更新。例如,可能會有新的數(shù)據(jù)源加入進來,或者現(xiàn)有的數(shù)據(jù)源的格式和結構會發(fā)生變更,或者升級分析組件來提升性能和準確性。這些都會導致管道組件的持續(xù)變化和更新。在管道演化過程中提供可追蹤性和可再現(xiàn)性會成為一個挑戰(zhàn)。管道開發(fā)人員可能想檢查管道的歷史,用于比較更新前后有什么不同。另外,如果有必要,每個數(shù)據(jù)處理組件應該能夠回滾到上一個版本。
Pipeline61
為了解決這些挑戰(zhàn)性問題,Pipeline61使用了三個主要的組件:執(zhí)行引擎觸發(fā)器、監(jiān)控器,以及管道管理器。數(shù)據(jù)服務提供了統(tǒng)一的數(shù)據(jù)IO層,用于完成枯燥的數(shù)據(jù)交換以及各種不同數(shù)據(jù)源之間的轉換工作。依賴和版本管理器為管道里的數(shù)據(jù)和組件提供了自動化的版本控制和依賴管理。Pipeline61為開發(fā)人員提供了一套管理API,他們可以通過發(fā)送和接收消息進行管道的測試、部署和監(jiān)控。
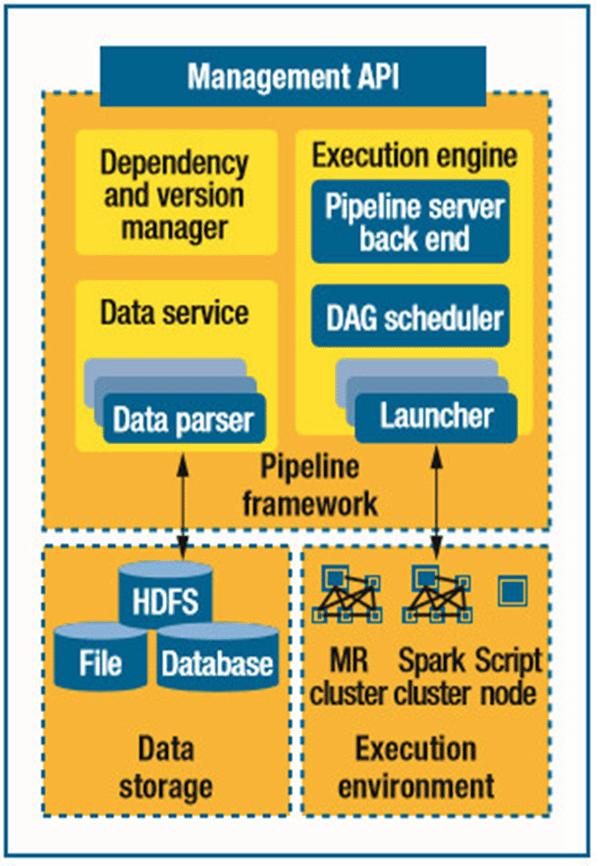
圖2. Pipeline61架構。Pipeline61框架旨在為在異構的運行環(huán)境里維護和管理數(shù)據(jù)管道減少精力的投入,而不需要重寫原有的作業(yè)。DAG表示有向無環(huán)圖。
Pipe模型
Pipeline61將管道組件表示為pipe,每個pipe有一些相關聯(lián)的實體:
- pipe的名字必須是唯一的,而且要與pipe的管理信息具有相關性。名字里可以包含命名空間信息。
- pipe的版本信息會自動增長。用戶可以執(zhí)行指定版本的pipe。
- 管道服務器負責管理和維護pipe。pipe需要知道管道服務器的地址信息,在運行期間,它可以向管道服務器發(fā)送通知消息。
- 輸入和輸出URL里包含了pipe的IO數(shù)據(jù)所使用的協(xié)議和地址。協(xié)議表示持久化系統(tǒng)的類型,如HDFS(Hadoop分布式文件系統(tǒng))、JDBC(Java Database Connectivity)、S3(Amazon Simple Storage Service)、文件存儲和其他類型的數(shù)據(jù)存儲系統(tǒng)。
- IO數(shù)據(jù)的輸入格式和輸出格式指明了數(shù)據(jù)的讀取格式和寫入格式。
- 運行上下文指明了運行環(huán)境和運行框架所需要的其他信息。
- 運行上下文與數(shù)據(jù)處理框架緊密相關。Pipeline61目前有三種主要的運行上下文:
- Spark運行上下文包含了一個SparkProc屬性,該屬性為SparkSQL提供了一個轉換函數(shù),用于將輸入RDD(彈性分布式數(shù)據(jù)集)轉化成輸出RDD,或者將輸入DataFrame轉換成輸出DataFrame。
- MapReduce運行上下文包含了一些結構化的參數(shù),指明了MapReduce作業(yè)的Mapper、Reducer、Combiner和Partitioner。可以使用key-value的形式添加其他參數(shù)。
- shell運行上下文包含了一個腳本文件或者內(nèi)聯(lián)的命令。Python和R腳本是shell pipe組件的子類型,它們可以使用更多由數(shù)據(jù)服務控制的輸入和輸出。shell pipe的不足之處在于,開發(fā)人員必須手動地處理輸入和輸出的數(shù)據(jù)轉換。
圖3展示了如何寫一個簡單的SparkPipe。基本上,開發(fā)人員只要使用SparkProc接口來包裝Spark RDD函數(shù),然后使用SparkProc初始化一個SparkPipe對象。

圖3. 如何寫一個簡單的SparkPipe。開發(fā)人員使用SparkProc接口包裝Spark RDD函數(shù),然后使用SparkProc初始化一個SparkPipe對象。
Pipeline61讓開發(fā)人員可以在邏輯層面將不同類型的pipe無縫地集成到一起。它提供了方法,用于將pipe連接起來形成管道。在將pipe連接起來之后,前一個pipe的輸出就變成了下一個pipe的輸入。在后面的案例學習部分,我們會展示一個更具體的例子。
執(zhí)行引擎
執(zhí)行引擎包含了三個組件。
管道服務器包含了消息處理器,用于接收和處理來自用戶和任務的消息。用戶可以通過發(fā)送消息來提交、部署和管理他們的管道作業(yè)和依賴。運行中的任務可以通過發(fā)送消息來報告它們的運行狀態(tài)。運行時消息也可以觸發(fā)一些事件,這些事件可以在運行期間調(diào)度和恢復進程。
有向無環(huán)圖調(diào)度器遍歷管道的任務圖,并將任務提交到相應的運行環(huán)境。一個任務會在它的所有父任務都被成功執(zhí)行之后進入自己的執(zhí)行調(diào)度期。
任務啟動器為pipe啟動執(zhí)行進程。目前,Pipeline61使用了三種類型的任務啟動器:
- Spark啟動器會初始化一個子進程,作為執(zhí)行Spark作業(yè)的驅(qū)動進程。它會捕捉運行時狀態(tài)的通知消息,并將通知發(fā)送給管道服務器,用于監(jiān)控和調(diào)試。
- MapReduce啟動器會初始化一個子進程,用于提交由pipe指定的MapReduce作業(yè)。在將執(zhí)行狀態(tài)發(fā)送給管道服務器之前,子進程會等待作業(yè)執(zhí)行完畢,不管是成功還是失敗。
- shell啟動器會創(chuàng)建一系列進程通道,用于處理shell腳本或者由shell pipe所指定的命令。在這些進程結束或者任何一個進程失敗之后,相關的狀態(tài)消息將被發(fā)送給管道服務器。
開發(fā)人員可以實現(xiàn)新的任務啟動器,用于支持新的運行上下文:
- 可以使用由執(zhí)行框架(比如Hadoop和Spark)提供的API
- 在已經(jīng)啟動的進程里初始化子進程,并執(zhí)行程序邏輯。
理論上,任何可以通過shell腳本啟動的任務都可以使用進程啟動器來執(zhí)行。
數(shù)據(jù)服務
每個pipe在運行期間都是獨立執(zhí)行的。pipe根據(jù)輸入路徑和格式來讀取和處理輸入數(shù)據(jù),并將輸出結果寫入指定的存儲系統(tǒng)。管理各種IO數(shù)據(jù)的協(xié)議和格式是件枯燥的事情,而且容易出錯。所以,數(shù)據(jù)服務為開發(fā)人員代勞了這些工作。
數(shù)據(jù)服務提供了一組數(shù)據(jù)解析器,它們根據(jù)給定的格式和協(xié)議在特定運行環(huán)境里讀取和寫入數(shù)據(jù)。例如,對于一個Spark pipe來說,數(shù)據(jù)服務使用原生的Spark API來加載文件本文到RDD對象,或者使用SparkSQL API從JDBC或JSON文件加載數(shù)據(jù)到Spark DataFrame。對于Python pipe來說,數(shù)據(jù)服務使用Python Hadoop API加載CSV文件的數(shù)據(jù)到HDFS,并轉換成Python DataFrame。基本上,數(shù)據(jù)服務是將數(shù)據(jù)協(xié)議和格式映射到特定運行環(huán)境的數(shù)據(jù)解析器。
我們可以擴展數(shù)據(jù)服務,實現(xiàn)并注冊新的數(shù)據(jù)解析器。一些數(shù)據(jù)解析工具,如Apache Tika,可以作為數(shù)據(jù)服務的補充實現(xiàn)。
依賴和版本管理器
對于管道管理員來說,管理和維護管道生命周期是一件很重要的事情,同時也很復雜。 為了解決管道管理方面存在的痛點,依賴和版本管理器可以幫助用戶來維護、跟蹤和分析管道數(shù)據(jù)和組件的歷史信息。
依賴和版本管理器為每個管道維護了三種類型的信息。管道執(zhí)行跟蹤過程為管道應用程序的每一個運行實例維護了一個數(shù)據(jù)流圖。每個圖的節(jié)點都包含了實例組件的元數(shù)據(jù),比如啟動時間、結束時間和運行狀態(tài)。
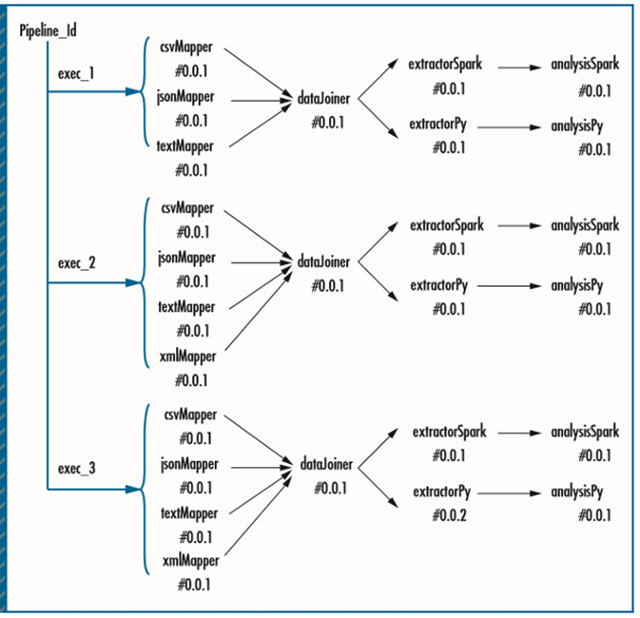
圖4. 在Pipeline61中維護的歷史和依賴信息,***部分。管道執(zhí)行跟蹤過程為管道應用程序的每一個運行實例維護了一個數(shù)據(jù)流圖。
管道依賴跟蹤過程(圖5a)為每個管道組件的不同版本維護著歷史元數(shù)據(jù)。它將每個組件的依賴信息保存成樹狀結構。保存在樹中的元數(shù)據(jù)包含了最近更新的名字、版本、作者、時間戳,以及運行依賴包。
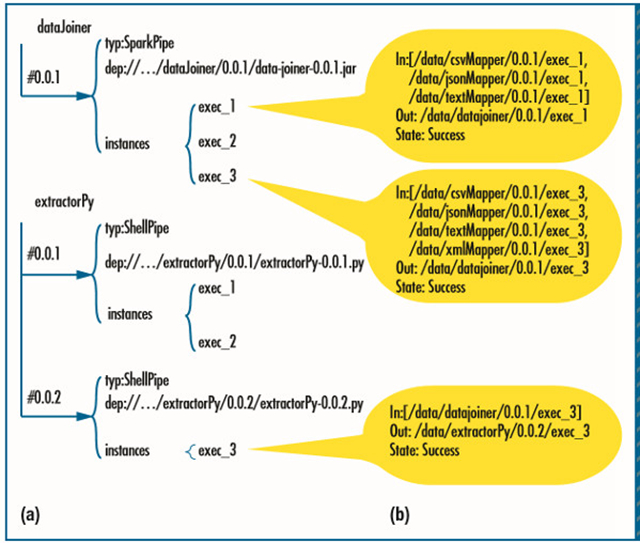
圖5. 在Pipeline61中維護的歷史和依賴信息,第二部分。(a) 管道依賴跟蹤過程為每個管道組件的不同版本維護著歷史元數(shù)據(jù)。(b) 數(shù)據(jù)快照包含了管道應用程序每一個運行實例的輸入輸出位置和樣本數(shù)據(jù)。
數(shù)據(jù)快照(圖5b)包含了管道應用程序每一個運行實例的輸入輸出位置和樣本數(shù)據(jù)。
Pipeline61用戶可以通過這些歷史信息來分析管道歷史,并通過重新運行舊版本的管道來重新生成歷史結果。
案例學習
以下的案例學習展示了Pipeline61的效率和優(yōu)勢。示例使用了來自不同組織的三種格式的數(shù)據(jù)源,包括CSV、文本和JSON。兩組數(shù)據(jù)科學家使用少量手寫的MapReduce和Python程序來對整體數(shù)據(jù)集進行分析。我們引入了我們的管道框架,用于自動執(zhí)行管道任務和管道管理。圖6展示了我們是如何在Pipeline61里指定管道的。

圖6. 在Pipeline61里指定管道。在相關的案例學習里,兩組數(shù)據(jù)科學家使用少量手寫的MapReduce和Python程序來對整體數(shù)據(jù)集進行分析。
首先,我們指定了三種數(shù)據(jù)映射器——csvMapper、jsonMapper和textMapper——用于處理不同格式的輸入數(shù)據(jù)。我們指定了三個MapReduce pipe,并將三種mapper分別作為數(shù)據(jù)解析器傳遞進去。
接下來,我們使用RDD函數(shù)DataJoinerProc指定了一個叫作dataJoiner的Spark pipe,用于組合三種mapper的輸出結果。
***,我們指定了兩組分析pipe組件,從dataJoiner那里消費輸出結果。因為每個分析分支關注不同的輸入特征,我們?yōu)槊總€分析組件添加了一個特征抽取器。然后我們將這兩個分析組件實現(xiàn)為Python pipe和Spark pipe。***,我們使用連接操作將這些pipe連接在一起,組成了整體的數(shù)據(jù)流。
在這個場景里,如果使用現(xiàn)有的管道框架,比如Crunch和Cascading,那么開發(fā)人員需要重新實現(xiàn)所有的東西。這樣做存在風險,也非常耗時。它不僅對重用已有的MapReduce、Python或shell腳本程序造成限制,而且也對數(shù)據(jù)分析框架(如IPython和R)的使用造成約束。
相反,Pipeline61專注于管理和管道化異構的管道組件,所以它可以顯著地減少集成新舊數(shù)據(jù)處理組件所需要的投入。
管道后續(xù)的開發(fā)和更新也會從Pipeline61的版本和依賴管理中獲得好處。例如,如果開發(fā)人員想要更新一個組件,他們可以從數(shù)據(jù)快照歷史中獲得組件***的輸入和輸出樣本。然后,他們基于樣本數(shù)據(jù)實現(xiàn)和測試新的程序,確保新版本組件不會對管道造成破壞。
在將更新過的組件提交到生產(chǎn)環(huán)境之前,開發(fā)人員可以為新組件指定一個新的管道實例,并將它的輸出結果與生產(chǎn)環(huán)境的版本進行比較,對正確性進行雙重檢查。除此之外,如果新組件在部署之后出現(xiàn)錯誤,管道管理器可以很容易地回滾到前一個版本。管道服務器自動維護著每個組件的歷史數(shù)據(jù)和依賴,所以可以實現(xiàn)回滾。
這種DevOps風格的支持對于維護和管理管道應用程序來說是很有意義的,而現(xiàn)有的管道框架很少會提供這些支持。
不過Pipeline61也存在不足。它不檢查各個數(shù)據(jù)處理框架數(shù)據(jù)結構的兼容性。到目前為止,開發(fā)人員在進行管道開發(fā)時,必須手動對每個pipe的輸入和輸出進行手動測試,確保一個pipe的輸出可以作為下一個pipe的輸入。為了解決這個問題,我們打算使用現(xiàn)有的結構匹配(schema-matching)技術。
當然,在管道運行期間,大部分中間結果需要被寫到底層的物理數(shù)據(jù)存儲(如HDFS)里,用于連接不同運行上下文的pipe,同時保證管道組件的可靠性。因此,Pipeline61的管道運行比其他框架要慢,因為其他框架獨立運行在一個單獨的環(huán)境中,不需要與外部系統(tǒng)集成。我們可以通過只保存重要的數(shù)據(jù)來解決這個問題。不過,這需要在可靠性和歷史管理完整性之間做出權衡。