













打通MySQL架構和業務的任督二脈,做個DBA高手!
目前,在很多 OLTP 場景中,MySQL 數據庫都有著廣泛的應用,也有很多不同的使用方式。
從數據庫的業務需求、架構設計、運營維護、再到擴容遷移,不同的 MySQL 架構有不同的特點,適應一定的業務場景,或者解決一定的業務問題。
DBA 作為數據庫架構的設計、實施、維護人員,不僅要對各種 MySQL 架構非常熟悉,還要了解業務,對于不同的業務有一定的劃分和認識,并根據業務特點和架構特點,合理選擇和使用 MySQL,滿足業務需求。
本文從以下三個方面對 MySQL 數據庫和業務場景進行探討和說明:
- MySQL 數據庫常見架構
- 業務環境分類
- 業務與架構結合使用原則
讓大家先分別對 MySQL 的架構和業務分類有所了解,然后再將兩者貫通起來,使得能夠在進行業務與 MySQL 架構設計時綱舉目張,讓用戶可以用合適的技術解決支撐業務需求。
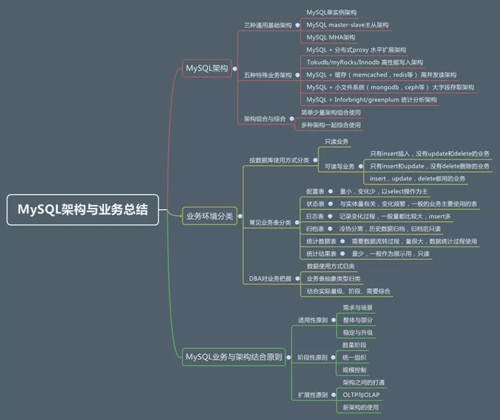
MySQL 數據庫常見架構
為了對 MySQL 數據庫常見架構,能夠有比較清晰的認識,下面先從 MySQL 三種通用基礎架構、五種特殊需求架構、架構組合與綜合使用三個方面進行說明。
MySQL 三種常見基礎架構
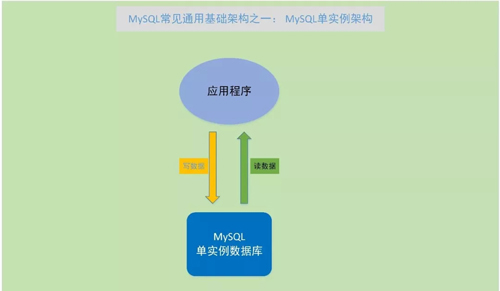
MySQL 單實例架構
MySQL 單實例,就是在服務器上部署一個 MySQL 實例來對外提供服務,這是最開始接觸 MySQL 數據庫會使用的方式,也是常見學習、研究 MySQL 數據庫的使用方式。
MySQL 單實例的使用方式,是 MySQL 數據庫使用的***階段,通常這種情況下,MySQL 數據庫與應用程序會在同一個服務器上。
這種方式主要好處就是部署和使用簡單,直接通過編譯安裝,或者二進制包解壓安裝,很快就可以有一個可以使用的 MySQL 數據庫環境。
同時,這種方式,依賴性少,不需要依賴其他第三方工具或者軟件,維護和故障定位也比較容易。
熟悉和掌握好 MySQL 單實例環境的技能,也是維護其他 MySQL 架構的基礎。
需要注意的是,MySQL 單實例在學習和開發環境可以使用一下,但這種方式的可用性和災備性較弱,如果作為業務系統使用的數據庫,盡量不要用這種方式。
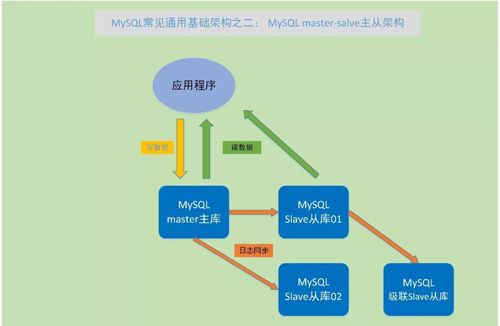
MySQL master-slave 主從架構
MySQL master-slave 主從環境,是在 MySQL 單實例環境的基礎上,將 MySQL 進行全庫備份,再恢復出一個或多個 MySQL 實例。
通過 change maste r命令,指定新恢復出的 MySQL 實例,從那個 MySQL 節點上讀取變化日志,并在本地應用,使新恢復的實例與原來的 MySQL 實例數據保持一致。
所以,原來的數據一致變化的實例,叫 master 主節點;從 master 節點獲取日志,并在本地應用,使數據與 master 階段保持一致的節點,叫 slave 從節點;這樣的架構環境,就叫 master-slave 主從環境。
master-slave 主從環境,是 MySQL 數據庫非常具有特色的功能,也是 MySQL 數據庫應用在生產環境的常見架構。
通過 master-slave 架構,就可以使線上數據庫的數據有了多份,起到了一定的數據備份功能。
Slave 從庫數據變化只通過應用日志實現,一般不會主動產生寫數據的情況,但可以提供對外數據讀服務,這樣通過增加幾個 slave 從庫,讓只進行數據讀取的業務到 slave 從庫上查詢,可以大大提高業務的讀性能和吞吐量。
在互聯網行業中,非常多的數據讀操作遠高于數據寫操作的業務場景,通過在 master 主節點寫數據,在 slave 節點上讀數據,進行這種讀寫分離的架構,可以很好地滿足業務需求。
當然,MySQL 的 master-slave 主從架構,具體實現也可以非常靈活,1 個 master 主節點,可以有 1 個或多個 slave 從節點。
而一個 slave 節點,也可以當做其他節點的 slave 節點,如果一個 slave 節點后面再有其他節點當做這個節點的 slave 從節點,就叫做級聯復制。
MySQL 的 master-save 架構,在 MySQL 單實例架構的基礎上,提高了 MySQL 數據庫的性能、可用性和可擴展性,同時也為 MySQL 數據庫追求更高的可用性,提供了基礎保障。
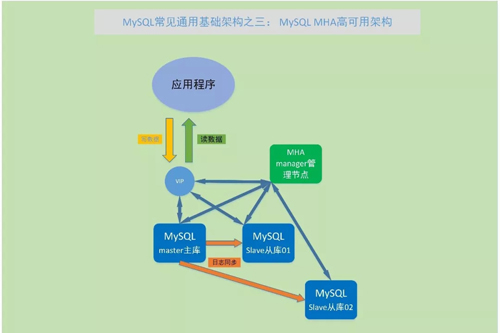
MySQL MHA 高可用架構
雖然 MySQL 數據庫的 master-salve 主從架構,使數據庫有了多份,但這些 maste 主節點和 slave 從節點之間,仍然是相對獨立的,尤其是 master 主節點如果出現故障了,仍然是不能對外提供數據庫服務的。
為了應對各種故障和特殊情況,實現數據庫更高的可用性,就需要在 master-slave 的基礎上,通過其他組件來實現更高的可用性。
MySQL 高可用性的方案比較多,但目前比較主流、比較成熟的方案,還是 MySQL + MHA 高可用架構。
簡單來說,為了實現更高的可用性,就要在 master-slave 主從環境的基礎上,將業務連接 master 的 IP,有 master 主機的實際 IP,變成虛擬的 VIP 或者域名。
應用程序通過 VIP 訪問數據庫,進行數據讀寫,在正常情況下,業務在 master 上進行讀寫;如果 master 節點出現故障,高可用組件會監測到這個故障,并將 VIP 切換到 slave 從庫上。
同時在 slave 從庫上進行日志的傳輸和應用,保證 slave 上的數據,與 master 節點故障前的數據盡量一致,這樣切換后新的 slave 節點就仍然可以對外提供數據庫服務。
當然,對于具體實現來說,在 MySQL 的 master-slave 主從結構外,VIP 和數據庫日志追平的方案也是有多種實現方式,也可進行各種深入定制,甚至一些公司不使用開源軟件,直接自己開發來實現高可用組件的各個功能。
目前 MySQL + MHA 這種高可用實現方式,是比較主流和成熟的實現方式,后面也可能會有一些其他更加完善的高可用實現方式,但都可以歸類到實現提高可用性這個范圍。
小結:對于 MySQL 數據庫的各種通用性需求,這三種基礎架構都可以很好地滿足,換句話說,這是 MySQL 數據庫架構中必須要用到和掌握的三種基礎架構。
五種特殊業務需求架構
通過 MySQL 中這三種常見基礎架構,絕大多數 MySQL 數據庫場景和問題,都可以很好得到滿足和解決。
但一些特殊的場景,或一些特殊的問題,也可以使用除 MySQL 數據庫以外的其他數據庫、專門某一類或幾類問題的解決方案。
針對這些特殊的業務需求,接下來我會先從要解決的問題進行描述和說明,然后再提出對應的解決方案。
MySQL + 分布式 Proxy 水平擴展架構
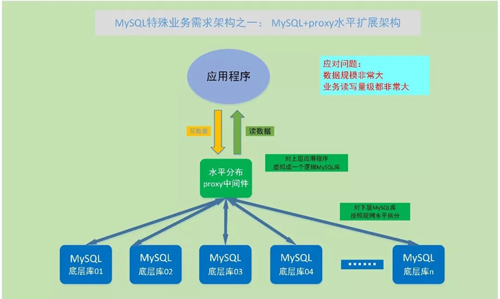
問題:如果業務規模進一步擴大,讀寫量級尤其是寫的量級達到非常大的地步。
比如每秒數據寫入幾十萬,甚至幾百萬,每天的數據量有幾億甚至幾十億的規模,這樣的讀寫就遠遠不是一個 master 節點可以支撐的,這時就必須要進行擴展了。
一般來說,MySQL 的擴展可分為:按照不同業務進行垂直拆分的垂直擴展,和通過一定的分庫分表策略實現的庫表水平擴展兩種方式。
這兩種方式可以單獨使用,也可以結合使用。但如果是解決大量數據和高并發讀寫,主要方式還是 MySQL 水平擴展。
MySQL 水平擴展的思路:在一個服務器上的 database 庫和 table 表,總會受到一臺服務器的資源限制,即使服務器的硬件各方面都達到頂配,也還是會有瓶頸。
對于業務訪問來說,如果有一個 Proxy 代理層或者中間件層的一個 database 和一個 table,通過代理層按照一定的規則映射和轉換,轉換成底層多臺服務器上的多個 database 和多個 table,這樣就相當于多臺服務器共同支撐一個業務,可支持的容量就與底層服務器的數量有關。
在 Proxy 代理沒有到瓶頸的情況下,底層服務器數量越多,整個水平擴展集群的性能和容量也會越多,幾乎可以線性擴展。通過這樣的思路,就可以解決大量數據存儲和并發的問題。
具體實現來說,水平擴展集群除了 MySQL 數據庫,需要一個分布式 Proxy 中間件,這種水平擴展中間件種類也比較多,MySQL 官方和一些大的的公司都有開發。
我們用的比較多的是 MyCAT 中間件,對于底層的分片,可以有幾十個、幾百個甚至幾千個。
當然,水平擴展可以解決大數據量的問題,需要有分片策略,那相應地,也會有使用這種策略的限制,比如片鍵選擇,跨節點訪問,分布式事務等問題,需要與業務進行對應結合和考慮后,才可以很好地使用。
TokuDB/MyRocks/InnoDB 高性能寫入架構
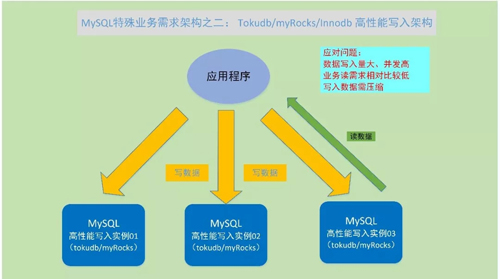
問題:MySQL 數據庫水平拆分,可以對于大數據量的讀寫進行線性擴展,相應地底層服務器數量也需要比較多。
但對于數據寫入量非常大,數據讀很少,數據總量大的情況,使用高性能寫入架構,會更合適一些。
業務數據寫入量非常大,讀取量非常高的情況,一般主要對數據 insert 寫入性能,同時對數據壓縮效率有特別高的要求。
這種特殊的寫入要求,需要對數據寫入有特殊的優化和設計,并且有比較好的壓縮效率和算法,能夠將寫入的大量數據進行壓縮,節省空間。這種寫入架構, 通常可以看做是 MySQL 數據庫的一種特殊的存儲引擎。
具體到實現而言,MySQL 的高性能寫入集群,可以使用 TokuDB 存儲引擎。近幾年 Facebook 也開源了其內部實現的 MyRocks,可以作為高性能寫入的存儲引擎。
MySQL 默認的 InnoDB 存儲引擎,在新的 5.7 及以后版本優化后,寫入性能和壓縮性能也有了更高的性能,也可以作為數據寫入的一種選擇。
MySQL + 緩存(Memcached、Redis等) 高并發讀架構
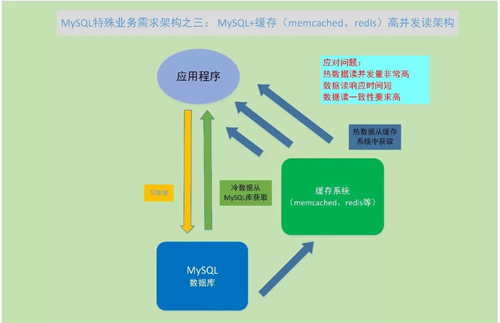
問題:如果業務訪問 MySQL 中的某一些少量熱數據,訪問的并發量非常高,訪問的時效性,數據的一致性要求都非常高。
這時候使用 MySQL 數據庫本身支持這些數據讀取,可能會在并發性、時效性上出現瓶頸,所以就可以使用緩存系統結合 MySQL 來使用。
緩存系統是將 MySQL 數據庫中的少量熱數據存放到內存當中,由于內存的 IO 效率遠高于硬盤的 IO,相應的 CPU 消耗也會少很多,這樣緩存系統中響應一次業務請求的時間,會遠少于直接從 MySQL 數據庫訪問需要的時間。
于是緩存系統就可以支撐熱數據的高并發訪問,數據寫還是寫入 MySQL 數據庫中,數據讀操作,優先讀取緩存。
如果緩存中有,則直接從緩存中返回結果;如果緩存中沒有,則從 MySQL 數據庫中讀取數據返回應用,并把數據結果再放到緩存的內容中。
具體實現來說,緩存系統常用的技術架構有 Memcached 和 Redis:
- Memcached 是比較經典的緩存系統,在之前常與 LAMP、LNMP 流行架構結合使用。
- Redis 是幾年新興的 Key-Value 鍵值型 NoSQL 數據庫,除了作為緩存,還可以持久化作為 Key-Value 數據庫使用。
MySQL + 小文件系統(MongoDB、Ceph等) 大字段存取架構
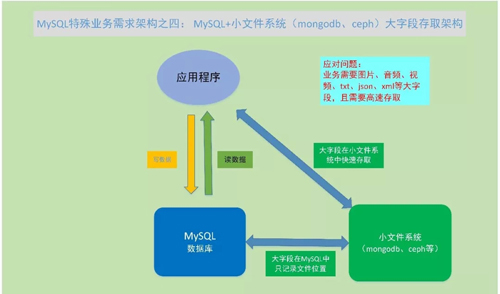
問題:在 MySQL 數據庫中,通常是存儲符合關系型數據庫原理的小字段,比如數值型、字符型數據。
但在實際環境中,除了這些常用字段,還會有一些大字段,比如用戶頭像這種圖片文件、上傳的音頻、視頻文件、帖子內容等大 text 字段,另外還有一些 JSON 文件、XML 文件等。
這些可以以二進制形式存儲在 MySQL 數據庫中,但讀取和管理都會比較麻煩。這時,就可以使用小文件系統來結合 MySQL 來使用。
小文件系統,是可以存儲并快速訪問結構化數據的系統。對于圖片、音頻、視頻、TXT 文件、JSON 文件、XML 文件等大字段,一般就只有簡單的讀寫操作,將這些字段存入到小文件系統中,并將對應的訪問鏈接存入到 MySQL 數據庫的表中。
這樣通過數據庫表,可以快速讀寫文件位置信息,在小文件系統中,通過文件位置信息,可以實現對大字段的快速讀寫訪問。
具體實現而言,小文件系統也有很多技術軟件,比較常見的有 MongoDB 文檔型 NoSQL 數據庫、Ceph 分布式小文件系統等。
MySQL + Inforbright/Greenplum 統計分析架構
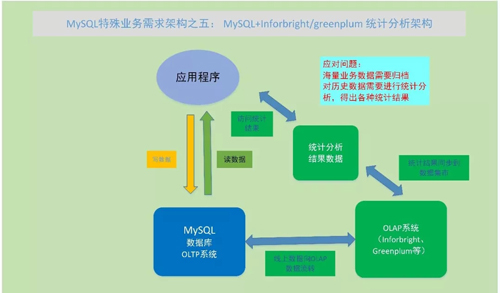
問題:在 MySQL 數據庫上實時響應業務需要的查詢,通常是指 OLTP 業務,但對于已經產生的數據,通常會在第二天之后,有結果匯總和統計分析需求。
這類 OLAP 需求通常執行頻率較低,但每次執行消耗的資源很大,如果與 OLTP 一樣在一個系統上運行,就會造成這兩大類業務的相互影響。這時就可以使用 MySQL 數據庫與 OLAP 統計業務分類結合的架構。
MySQL 產生了業務數據后,通常需要在第二天,要對前一天的數據進行各個角度、各個維度的統計、聚合、分析,以體現和反映業務的運營情況。
這是讓 MySQL 支持線上 OLTP 業務,通過數據流轉程序,將每天產生的數據流轉到離線的數據倉庫系統中,在數據倉庫系統中,進行各種數據統計分析、結果匯總,并將數據統計結果再流轉到結果展示庫中。這樣就可以很好地實現線上 OLTP 和線下 OLAP 的結合使用和執行。
具體實現而言,對于 MySQL 數據庫可以結合的 OLAP 數據倉庫架構,可以選用 Inforbright 數據倉庫,也可以選用 Greenplum 分布式 MPP 數據庫倉庫。
相對而言,Inforbright 數據倉庫比較輕量級,與 MySQL 使用類似;Greenplum 分布式 MPP 數據倉庫可以支撐海量數據的統計分析,功能、性能、容量等也比 Inforbright 要更強一下,成本也更大一些。
小結:MySQL 五種特殊業務架構,可以說是在 MySQL 三種常見的、通用的架構基礎上,面對特殊的業務場景,遇到特殊的問題,進行針對性解決:
- 對于大量數據讀寫,可以采用水平擴展架構。
- 對于有大量數據寫入需求,可以采用 MySQL 高性能寫入架構。
- 對于熱數據的高并發、快速響應的需求,可以采用 MySQL+緩存架構。
- 對于特殊的大字段存取需求,可以采用 MySQL+小文件系統架構。
- 對于離線統計分析需求,可以采用 MySQL+統計分析架構。
架構組合與綜合使用
MySQL 三種比較通用的基礎架構和五種特殊需求架構,都可以根據場景單獨使用,也可以根據特定的場景進行組合幾種架構使用,或者綜合起來一起使用。
架構組合
對于只有一兩種特殊情況的架構,選擇基礎架構和特殊架構的簡單組合就可以了,生產環境中可用到的架構組合類型有:
- MySQL+MHA 高可用架構與 MySQL 分布式 Proxy 水平擴展架構組合。
- MySQL+MHA 高可用架構與 MySQL 小文件系統大字段存取架構組合。
- MySQL+MHA 高可用架構與 MySQL 緩存高并發讀架構組合。
- MySQL 分布式 Proxy 水平擴展架構與 MySQL 小文件系統大字段存取架構組合。
- MySQL 分布式 Proxy 水平擴展架構與 MySQL 緩存高并發讀架構組合。
- MySQL 高性能寫入架構與 MySQL Inforbright/Greenplum 統計分析架構組合。
架構綜合
如果是比較復雜的業務場景,幾種特殊的數據庫架構可以綜合起來使用:
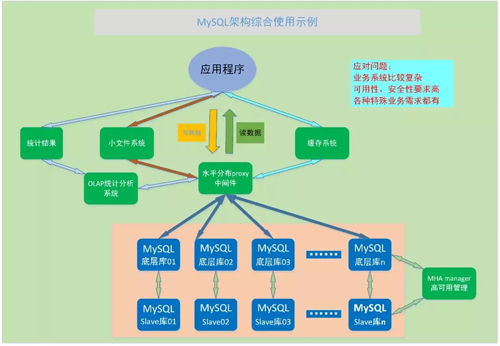
MySQL+MHA 高可用架構 、MySQL 分布式 Proxy 水平擴展架構、MySQL 緩存高并發讀架構、MySQL 小文件系統大字段存取架構、MySQL Inforbright/Greenplum 統計分析架構。
業務環境分類
***部分對 MySQL 的架構進行了說明,這是對 MySQL 數據庫本身的了解,算作“知己”。
所有的數據庫系統提供服務的對象都是業務系統,所以 DBA 要對業務系統進行了解,對業務的特點和適合的場景,做到心中有數,可以算作是“知彼”。做到知己知彼,就能更好地貫通兩者了。
從數據庫使用推導數據使用分類
從數據庫操作角度看,業務系統對于數據庫的操作,大的方面可以分為“讀數據”和“寫數據”兩類。
展開來說,寫數據也可以具體分為:insert 插入數據、update 修改數據、delete 刪除數據三種情況。
所以,數據庫的使用也可以細分為:增 insert、刪 delete、改 update、查 select 四種情況。
依據業務系統對數據的操作分類,就可以對業務系統進行歸類:
只讀業務系統
只讀是指只有查詢 select,沒有數據修改的情況。這種情況,是數據庫中已經存在一些數據,并且這些數據只作查詢或展示用,不會有任何數據變化。
比如緩存中的數據、歸檔后的數據、歷史結果數據、統計結果數據等,都是只能進行查詢和展示,不會再發生數據變化的。
可讀寫業務系統
按照寫操作的具體情況,可以對可讀寫業務系統分成三類:
- 只有插入 insert,沒有 update 和 delete 的可讀寫業務系統,這種情況是指數據表的數據只會增加,且表中的數據不能再變化,不會再有修改或者刪除操作;比如操作記錄表、狀態變化記錄表、留言記錄表等。
- 有 insert 和 update,沒有 delete 的可以讀寫業務系統,這種情況是指數據表中的數據,可以進行增加和修改,但數據一旦產生,可以變化,但不能修改。
這也是一種常見的數據庫設計思路,即數據表可以有失效,但生效刪除,并不是真正從數據表中刪除,而是修改了表中表示狀態位的列值,這樣就可以保證數據一直具有可回溯性。
- insert、update、delete 都有的可讀寫業務系統,這種情況是指數據表中的數據可進行各種操作,可以查詢,也可以進行各種變化,添刪改除各種操作也都可以進行。
常見業務表分類
從業務角度對表進行分類,雖然不同的應用程序對表的使用不同,但還是能夠抽象成為幾大類表。
配置表
這種表通常存放業務一些基礎的配置信息或者字典信息。表的數據量一般都比較小,修改變化的操作不太頻繁,通常都是 select 查詢操作。
狀態表
這種表通常存放在業務系統中實體讀象的狀態信息,常見的有用戶信息表,訂單信息表等。這種表的數據量與實體讀象的規模有直接關系,比如一個 APP 有多少注冊用戶,通常這個 APP 的用戶表都會有多少條記錄。
狀態表的變化通常比較頻繁,而且 insert、update、select 操作都會有,delete 操作是否有,通常會根據業務情況的規定決定。
日志表
這種表通常用來記錄業務系統中某種實體的狀態信息,常見的有用戶登錄表、充值信息記錄表等。
這種表的數據規模通常比較大,而且如果業務狀態變化頻繁,記錄的變化信息比較多,這種表的數據量和插入性能都要求比較高。
日志表的操作,通常會以 insert 操作為主,個別業務會對日志表進行查詢。MySQL 五種特殊需求架構中的高性能寫入架構,主要就是應用這種表的需求。
歸檔表
這種表,是將上面三種 OLTP 業務表的數據進行歸檔或者冷熱分離的表。對線上業務三類表進行數據歸檔、冷熱分離。
一方面可以控制線上業務表的數據規模,保證業務表性能;另一方面進行歸檔后,可用于對歸檔歷史數據進行更好的查詢反映和支持。
歸檔表的數據量大小與對應的線上表大小、歸檔周期有關。歸檔表的操作,除了歸檔過程的數據加載外,主要就是 select 查詢操作了,歸檔后就算是只讀表。
統計數據表
統計數據表,是指業務有離線統計分析需求時,需要將各種線上表和歸檔表的數據,通過ETL過程流轉到線上 OLAP 統計分析系統中的原始數據表。
這類表通常數據量會非常大,一個 OLAP 統計分析平臺會匯總多個線上業務系統的數據進行統計分析。統計數據表的操作,除了數據流轉動作外,主要就是各種統計分析程序的訪問計算。
統計結果表
統計結果表是在業務有離線統計分析需求時,各種統計分析過程訪問統計數據表中的數據,按照一定的邏輯進行統計分析后的結果數據。
這種統計結果數據,通常數據量會比較小。統計結果表的操作,處理結果流轉動作外,主要就是供訪問接口進行 select 查詢。
通過對業務表類型的梳理,可以對所有的業務系統進行一個大體的劃分,做到心中有數。
DBA 對業務的把握
通過數據使用方式將業務系統劃分為四類,再通過業務常見表類型劃分,就可以對通用的業務使用數據庫有一個整體的了解。但對于具體的業務場景,還需要根據每個公司具體的實際情況進行具體確認和考慮。
大多數情況下,某一種具體的業務都可以根據情況歸入某一種業務類型中,只是每個業務具體的量級會有不同,大家需要先了解具體業務環境中的量級,再根據業務類型與 MySQL 架構的使用情況,進行對應就可以了。
如果實際環境中確認有不在現有分類中的情況,則可以通過現有的思路,進行新的類型劃分和架構對應。
業務與架構結合使用原則
上面兩部分通過對 MySQL 各種架構進行說明,并通過對業務環境的分類,可以讓大家對 MySQL 架構和業務環境本身有一定的了解。
下面我將就我在架構設計和運維當中兩者結合的使用原則,對 MySQL 業務和架構的結合使用進行說明。
適用性原則
適用性原則就是在考慮某一個具體業務場景具體使用哪一種或者幾種業務場景時,我們要盡量使用合適的技術架構解決合適的問題。
需求與場景
MySQL 的三種通用基礎架構,適用的場景多一些。但通用業務場景在數據量級、訪問規模、讀寫方式等發生比較大的變化時,就變成了有特殊需求的場景,可以考慮使用某種特定場景對應的 MySQL 架構技術,盡量保證適用性。
反之,如果實際業務在量級、規模、讀寫方式還沒有達到非常特殊的場景時,盡量使用通用的基礎架構就可以滿足業務需求,也可以降低系統復雜度和隱患。
整體與部分
不論對于一個業務系統,還是 MySQL 數據庫架構而言,都要從整體和部分兩個角度進行看待和考慮。
一個業務系統,首先是一個整體,從整體上看各種業務需求和使用方式,把握好整體,然后再考慮具體的需求。
如果沒有特殊的需求,則可以按照通用場景來設計和考慮;如果某一部分有特殊的需求,則可以把這部分內容單獨劃分出來,進行對應的架構設計。
多個通用和特殊的架構,相互組合,完成一個對業務系統支撐的架構總體。
穩定與升級
一般情況下,業務系統都是先用通用架構進行數據支持,在通用架構適用時,業務系統也可以穩定運行。
在業務系統不斷運行過程中,有新業務場景需求產生時,要綜合考慮保證現有業務穩定性、以及升級業務系統到新架構的步驟和階段。
一般不要一下子全部升級,建議采用先測試、再上線、分批次逐步過渡和升級的方式。
階段性原則
業務系統的發展是有階段的,MySQL 數據庫架構的發展也是有階段的。不同階段關注的信息和主要處理思路都是不同的,從不同維度考慮階段性也是使用架構和業務的重要原則。
數量階段
數量是一個比較明顯的階段判斷指標。業務系統通常會有 DAU、UV、PV 等指標,來幫助判斷業務系統的規模。
數據庫系統、QPS、TPS、一個表的數據量、一個庫下的表數量、一個實例下的庫數量、總的實例數量、服務器數量,都是與架構結合比較緊密的指標。
以表數據量舉例:如果一個表運行一年,數量在 10 萬以下,就可以認為是小表了;數據量在 10 萬-1000 萬以上的,可以認為是中表。
數據量在 1000 萬以上,就可以認為是大表,這時就需要考慮歸檔或水平拆分了;如果數據量在 1 億以上,就必須要用特殊架構進行單獨處理了。
統一組織
在業務規模和數據規模都比較小的時候,若存在多種不同的架構,還是可以維護的。
但如果數據庫實例數量和業務模塊都大起來之后,統一一種或少數幾種數據架構就非常重要了。統一架構組織,可以讓業務系統和架構,更加容易控制和維護。
規模控制
業務發展到一定規模,底層架構中的數據庫都必須要控制規模,一個實例不能太大,一個表也不能太大,如果超過了約定好的規模,需要進行實力拆分,或者表拆分,以使實例和庫表都保持在統一設定的規模當中。
擴展性原則
應用業務隨著時間會不斷變化,底層的 MySQL 架構也需要隨著業務的變化能夠具有一定的擴展性,保持變化和擴展的空間,以不斷支持業務的發展。
架構之間的打通
從 MySQL 的三種基礎架構就可以看出來,MySQL 單實例架構→MySQL master-slave 主從架構→MySQL MHA 高可用架構,這中間是逐步演進的,有直接的依賴關系。
后續 Oracle 推出的 InnoDB Cluster 架構,也與這些基礎架構有直接演進關系。
其他五種特殊需求的架構,隨著業務分類的變化,特殊情況也可能發生變化,可根據這些變化從一種特殊架構調整成為另一種特殊的架構。
OLTP 與 OLAP
數據庫系統一般分為 OLTP 和 OLAP 兩大類,但實際在目前的業務系統和架構設計中,這兩種需求都是需要支持的。
只要建立好一個比較穩定、可靠的數據流轉體系,將這兩者打通,就可以很容易地實現 OLTP 和 OLAP 的互通,OLTP 的業務數據傳送到 OLAP 中進行統計,OLAP 的統計結果,再返回到 OLTP 中進行展示。
新架構的使用
MySQL 架構中除了常見的三種基礎架構和五種特殊架構,還有一些新的技術和趨勢來嘗試完善和解決現有架構的一些問題,比如 InnoDB Cluster 等技術,對 MySQL 的擴展和高可用會有更好的解決方式。
雖然目前這些新技術還沒有完全穩定和成熟,但在后續新技術架構穩定成熟后,可以很容易地將現有架構擴展成新的技術架構,這樣就可以更好地解決業務問題了。
后記
本文嘗試從 MySQL 架構,業務環境分類,MySQL 業務和架構結合使用原則三個方面對 MySQL 架構和業務進行了說明。
希望能夠從架構角度讓大家對架構和業務的理解,能夠更深一層、觸類旁通地面對和解決各種業務問題。
其中某些與架構關聯性不太大的具體細節,在本文中沒有完全展開,會在以后的文章中再進行說明。
作者:趙飛祥
介紹:現在競技世界從事數據庫相關工作, Oracle 10G OCP,11G OCM,Oracle YEP 年輕專家,8 年數據庫運維和架構經驗,對 MySQL、Oracle、PostgreSQL、Greenplum、MongoDB 等多種常見數據庫有豐富的運維實踐經驗,掌握與數據庫相關的前后端架構和 DevOps 實現技術,擅長數據庫架構設計、維護優化、數據流轉、Shell 和 Python 開發;樂于技術交流,以網名 yumushui 進行了大量的技術總結和思考分享。














