Redis 集群故障應急響應:從止損到恢復的全鏈路實戰方案
作者:一安
在高并發系統架構中,Redis集群作為核心緩存組件,承載著減輕數據庫壓力、提升響應速度的關鍵作用。一旦Redis集群整體宕機,海量請求將直接涌向數據庫,極易引發緩存雪崩連鎖反應,導致系統全面癱瘓。多數開發者對這一故障的認知僅停留在持久化恢復數據層面,卻忽視了系統可用性保障、臟數據規避等核心問題。
引言
在高并發系統架構中,Redis集群作為核心緩存組件,承載著減輕數據庫壓力、提升響應速度的關鍵作用。一旦Redis集群整體宕機,海量請求將直接涌向數據庫,極易引發緩存雪崩連鎖反應,導致系統全面癱瘓。多數開發者對這一故障的認知僅停留在持久化恢復數據層面,卻忽視了系統可用性保障、臟數據規避等核心問題。
本文將從故障應急視角,拆解Redis集群宕機后的完整處理流程,提供可落地的分步解決方案。
故障核心痛點:不止是數據丟失
Redis集群宕機并非單純的緩存不可用,其引發的連鎖問題需精準定位:
- 流量洪峰沖擊:失去緩存緩沖后,原本由Redis承載的高并發查詢直接穿透至數據庫,遠超數據庫處理能力,導致連接耗盡、查詢超時。
- 臟數據風險:集群宕機期間,業務系統仍會產生數據修改、刪除操作,若直接恢復RDB/AOF備份數據,將導致緩存與數據庫數據不一致。
- 功能可用性危機:核心業務與非核心業務流量混雜,可能因非核心功能占用資源,導致核心交易、用戶查詢等關鍵服務不可用。
- 恢復節奏失控:盲目重啟集群或放開流量,可能造成二次故障,延長系統不可用時間。
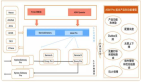
應急響應三步走:從止損到平穩恢復
 圖片
圖片
第一步:限流降級雙管齊下,守住數據庫防線
故障發生后,首要目標是控制流量規模,避免數據庫被擊垮,同時保障核心功能可用。
限流策略:精準控制請求峰值
 圖片
圖片
限流的核心是通過設定合理閾值,拒絕超出系統承載能力的請求。
- 閾值校準:需提前通過壓測明確無Redis支撐時系統的最大承載能力,限流閾值建議設為該峰值的70%~85%,預留安全邊際。
- 實施方式:通過網關層(如Nginx、Spring Cloud Gateway)配置限流規則,支持按接口維度、IP 維度進行流量控制,超出閾值的請求直接返回服務繁忙提示。
- 適配場景:適用于系統接口重要等級劃分不清晰的情況,實現簡單直接的流量管控。
比如Nginx:
http {
# 定義限流zone(10MB內存空間,速率100r/s)
limit_req_zone $binary_remote_addr znotallow=api_limit:10m rate=100r/s;
# 分布式限流標識(如用戶ID)
limit_req_zone $http_x_user_id znotallow=user_limit:10m rate=10r/s;
server {
location /api/ {
# 基礎限流(突發不超過50個請求)
limit_req znotallow=api_limit burst=50 nodelay;
# 用戶級限流
limit_req znotallow=user_limit burst=5;
# 連接數限制
limit_conn perip 20;
limit_conn perserver 1000;
proxy_pass http://backend;
}
}
}降級策略:棄車保帥聚焦核心
 圖片
圖片
降級是通過犧牲非核心功能,保障核心業務正常運行的取舍策略。
- 功能分級:提前將系統功能按重要性劃分為P0(核心交易)、P1(用戶查詢)、P2(推薦服務)、P3(統計分析)四個等級。
- 降級操作:通過配置中心實時調整參數,集群宕機時僅保留P0級功能,關閉P1~P3級非核心功能,減少數據庫訪問壓力。
- 關鍵原則:降級需通過配置中心動態調整,嚴禁現場修改代碼熱修復,避免引入新的故障風險。
策略選擇邏輯
- 若系統接口重要等級清晰,優先選擇降級策略,實現精細化資源分配。
- 若接口等級劃分模糊,直接采用限流策略,快速控制整體流量規模。
第二步:空集群預熱,規避臟數據陷阱
集群宕機期間的業務數據變更,導致原有的RDB/AOF備份數據已失效,直接恢復將引發數據不一致問題。此時需采用空集群預熱方案:
核心思路
 圖片
圖片
部署全新的Redis空集群(不加載舊備份數據),通過用戶實時請求逐步構建緩存,實現數據動態預熱。
預熱流程
- 業務系統接收用戶請求后,優先查詢新Redis集群。
- 緩存未命中時,查詢數據庫獲取數據并返回給用戶,同時將數據寫入Redis集群。
- 重復請求相同數據時,直接從Redis命中返回,逐步降低數據庫壓力。
- 持續監控緩存命中率,當命中率達到目標閾值(如60%),說明預熱效果顯著。
特殊場景例外
若Redis中存儲的數據僅包含添加和查詢操作,無修改、刪除邏輯,可直接恢復備份數據,無需空集群預熱,這類場景不會產生數據不一致問題。
第三步:分階段放開限制,平穩過渡至正常狀態
緩存預熱過程中,需根據集群數據恢復進度,逐步調整限流 / 降級策略,避免流量驟增導致系統波動。
限流場景的梯度恢復
假設正常狀態下限流閾值為5000,按緩存恢復進度分階段調整:
- 恢復0%(初始狀態):閾值設為1500,嚴控流量入口。
- 恢復20%:閾值調整至2000,適度放開流量。
- 恢復40%:閾值提升至2500,持續觀察數據庫壓力。
- 恢復60%:閾值調整為3000,接近正常水平。
- 恢復80%:閾值設為4000,基本恢復正常流量。
- 恢復100%:閾值恢復至5000,完全放開限制。
降級場景的功能恢復
按緩存恢復進度逐步開放功能等級:
- 恢復0%:僅開放P0級核心交易功能。
- 恢復30%:開放P0+P1級(核心交易 + 用戶查詢)。
- 恢復60%:開放P0+P1+P2級(增加推薦服務)。
- 恢復90%:開放全量功能(P0~P3級),恢復正常服務。
關鍵監控指標
整個過渡階段需實時監控數據庫狀態,避免壓力過載:
- 系統Load:反映服務器整體負載情況。
- IOPS:每秒磁盤讀寫次數,判斷存儲壓力。
- CPU利用率:避免CPU資源耗盡。
- 內存使用率:防止內存溢出(OOM)。
- 慢查詢數量:及時發現數據庫性能瓶頸。
完整故障處理流程復盤
- 故障發現:通過監控系統(如Prometheus+Grafana)實時檢測到Redis集群節點全部離線,觸發告警。
- 應急啟動:立即執行限流/降級策略,將流量控制在數據庫可承受范圍。
- 集群部署:快速搭建全新的Redis 空集群,配置與原集群一致的參數。
- 數據預熱:業務系統切換至新集群,通過實時請求動態構建緩存。
- 梯度恢復:根據緩存命中率和數據庫壓力,分階段調整限流/降級規則。
- 全面恢復:當緩存命中率達到正常水平(如90%),且數據庫指標穩定,恢復所有功能和限流閾值。
- 故障復盤:分析集群宕機原因(如硬件故障、配置錯誤、網絡問題),優化集群高可用方案(如增加從節點、配置哨兵模式、優化持久化策略)。
核心原則與避坑指南
- 持久化≠數據可用:RDB/AOF僅能恢復歷史數據,無法同步故障期間的實時變更,盲目恢復將導致臟數據。
- 恢復需循序漸進:無論是限流閾值調整還是功能開放,均需分階段進行,給系統留出緩沖適應時間。
- 配置中心是關鍵:降級、限流策略的調整必須通過配置中心動態生效,杜絕代碼熱修復。
- 提前壓測必不可少:需專門針對Redis集群宕機場景進行壓測,明確系統極限承載能力,為限流閾值設置提供數據支撐。
責任編輯:武曉燕
來源:
一安未來